SAP Hana Vora is a 'Big Data' In-memory reporting engine sitting on top of an Hadoop Cluster.
Data can be loaded into the Hadoop Cluster memory from multiple source e.g. HANA, The Hadoop File system (HDFS), remote files systems like AWS S3
With the release of SAP Hana Vora 1.2 it's now possible to graphically model views (e.g. joining multiple datasets) similar to a Hana calculation view.
The following link has all the details to get you started with Vora SAP HANA Vora - Troubleshooting
This blog contains a very basic introductory example of using the new graphical modelling tool.
The steps are:
- Create 2 example datasets in HDFS, using scala and spark
- Create Vora tables, linked to these files
- Model a view joining these tables, and filtering on key elements
Firstly the following 2 datasets need to be created for transactional and master data (reporting attributes).
Transactional Data
| COMPANYCODE | ACCOUTGROUP | AMOUNT_USD |
|---|---|---|
| AU01 | Revenue | 300.0 |
| GB01 | Revenue | 1,000.0 |
| US01 | Revenue | 5,000.0 |
| US01 | Expense | -3,000.0 |
| US02 | Revenue | 700.0 |
Master Data
| COMPANYCODE | DESCRIPTION | COUNTRY |
|---|---|---|
| AU01 | Australia 1 | AU |
| GB01 | United Kingdom 1 | UK |
| US01 | United States of America 1 | US |
| US02 | United States of America 2 | US |
In the following steps open source Zeppelin is used to interact with Vora, Spark and HDFS.
Open Zeppelin and create a new notebook.

Next create the sample data using Spark and Scala.
| Create sample Company Data and save to HDFS |
|---|
fs.delete(new Path("/user/vora/zeptest/companyData"), true) val companyDataDF = Seq( ("GB01","Revenue", 1000.00), ("US01","Revenue", 5000.00), ("US01","Expense",-3000.00), ("US02","Revenue", 700.00), ("AU01","Revenue", 300.00)).toDF("Company","AccountGroup","Amount_USD")
companyDataDF.repartition(1).save("/user/vora/zeptest/companyData", "parquet") |

| Create sample Company Master Data and save to HDFS |
|---|
fs.delete(new Path("/user/vora/zeptest/companyAttr"), true) val companyAttrDF = Seq( ("GB01","United Kingdom 1", "UK"), ("US01","United States of America 1", "US"), ("US02","United States of America 2", "US"), ("AU01","Australia 1", "AU")).toDF("Company","Description", "Country") companyAttrDF.repartition(1).save("/user/vora/zeptest/companyAttr", "parquet") |

Lets now check in HDFS that the directories/files have been created
| Directory listing in HDFS |
|---|
import org.apache.hadoop.fs.FileSystem import org.apache.hadoop.fs.Path val fs = FileSystem.get(sc.hadoopConfiguration) var status = fs.listStatus(new Path("/user/vora/zeptest")) status.foreach(x=> println(x.getPath)) |

Next use the %vora option in Zeppelin to create the Vora tables
| Create the Vora Tables |
|---|
%vora CREATE TABLE COMPANYDATA( COMPANYCODE VARCHAR(4), ACCOUNTGROUP VARCHAR(10), AMOUNT_USD DOUBLE ) USING com.sap.spark.vora OPTIONS ( tableName "COMPANYDATA", paths "/user/vora/zeptest/companyData/*", format "parquet" ) |
%vora CREATE TABLE COMPANYATTR( COMPANYCODE VARCHAR(4), DESCRIPTION VARCHAR(50), COUNTRY VARCHAR(2) ) USING com.sap.spark.vora OPTIONS ( tableName "COMPANYATTR", paths "/user/vora/zeptest/companyAttr/*", format "parquet" ) |

Next use the %vora option in Zeppelin to check the Tables have been loaded correctly
| Check the Vora Tables |
|---|
%vora show tables |
%vora SELECT * FROM COMPANYDATA order by COMPANYCODE , ACCOUNTGROUP DESC |
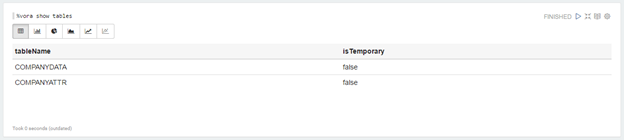

Now with the tables created we are ready to use the modelling tool
Launch the Vora tools (running on port 9225 on Developer edition)
Vora Tables created in Zeppelin or or other instances of the Spark context may not yet be visible in the Data Browser.
To make the visible then use SQL Editor and register the previously created tables using the following statement.
REGISTER ALL TABLES USING com.sap.spark.vora OPTIONS (eagerLoad "false") ignoring conflicts
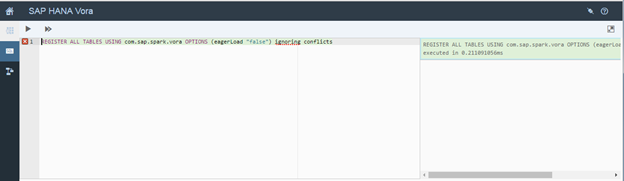
The tables are now visible for data preview via the 'Data Browser'.

Now the 'Modeler' can be used to create the view VIEW_COMPANY_US_REVENUE

In this example the modelling tool is used to:
- Join Transactional data and Master data on COMPANYCODE
- Filter by COUNTRY = 'US' and ACCOUNTGROUP = 'Revenue'
- AMOUNT_USD Results summarised by COUNTRY
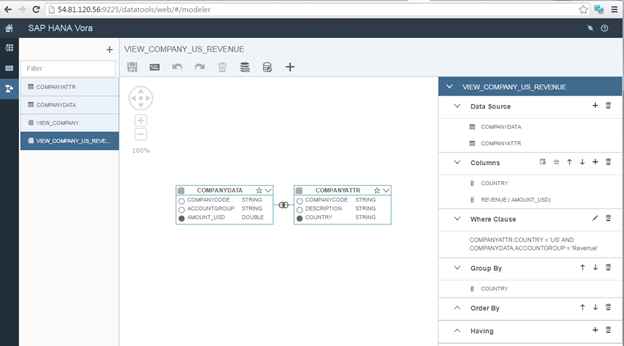
The generated SQL of the view can be previewed

Once saved the new view VIEW_COMPANY_US_REVENUE can be previewed via the 'Data Browser'.

The new view will be accessible via external reporting tools, Zeppelin and other Spark Context.
I hope this helps gets you started exploring the capabilities of Vora.